PDFファイルは日常的にビジネスや学習の場で多く使われていると思います。
しかし、PDFファイルの編集や変換は思ったより面倒で、専用のソフトウェアを使用している人も多いんじゃないでしょうか。
Pythonを使えば、PDFファイルを簡単に自在に操ることができます。
テキストの抽出、ファイルの分割や結合、さらにはWordファイルへの変換まで、Pythonを使えば簡単に実現できます。
この記事では、Pythonを使ってPDFファイルを操作する方法を、初心者の方にも分かりやすく解説します。基本的な操作を学べば、PDFファイルを思いのままに扱えるようになります。
0.事前準備
①まず、Pythonと必要なライブラリをインストールする必要があります。Pythonは公式サイトからダウンロードできます。
②その後、コマンドプロンプトやターミナルを開き、次のコマンドを実行してライブラリをインストールしましょう。
pip install pypdf
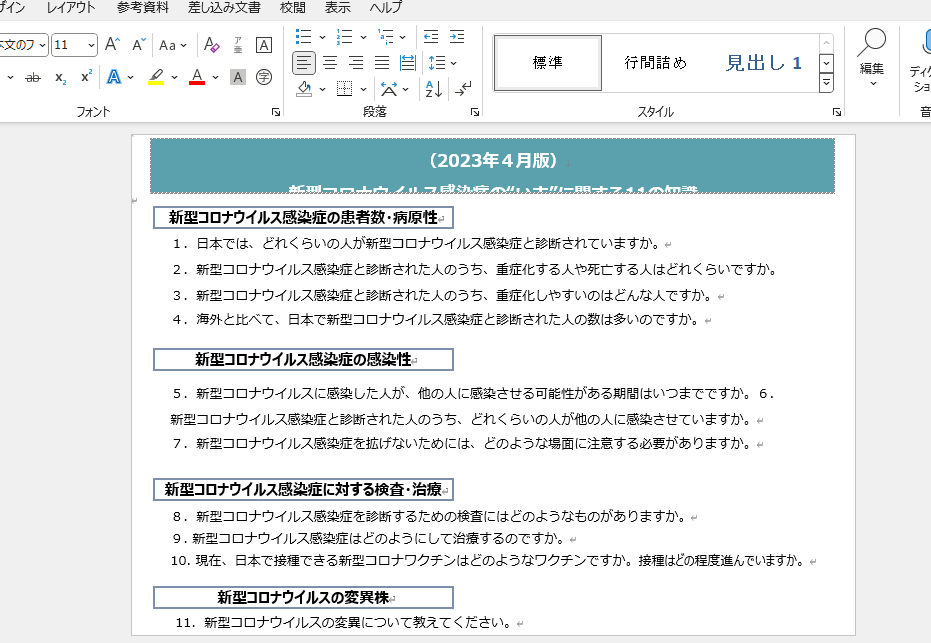
pip install pdf2docx③今回、操作するPDFファイルを用意します。今回は厚生労働省が公開している新型コロナウイルスの調査資料を操作したいと思います。
https://www.mhlw.go.jp/content/000927280.pdf
「新型コロナウイルス感染症の“いま”に関する11の知識」
以下のような形で、ローカルの任意のフォルダにPDF(sample.pdf)を格納し、今回プログラムを記載するPythonファイルを作成します。

これで準備は完了です。それでは、具体的なPDF操作の方法を見ていきましょう。
1. PDFからテキストを抽出する
PDFファイルからテキストを取り出したい場合があります。例えば、PDFの内容をコピーして別の文書に貼り付けたい時などですね。Pythonを使えば、この作業を自動化できます。
import pypdf
# PDFからテキストの抽出
reader = pypdf.PdfReader("sample.pdf")
# 1ページ目を取得してテキスト抽出
slide = reader.pages[0]
text = slide.extract_text()
print(text)このコードは、sample.pdfという名前のPDFファイルから、1ページ目のテキストを抽出します。pypdf.PdfReader("sample.pdf")でPDFファイルを読み込み、reader.pages[0]で1ページ目を取得します(Pythonの配列では、0から数え始めるので注意してください)。
そして、slide.extract_text()を使ってテキストを抽出し、print(text)で画面に表示します。

これで、PDFの1ページ目に書かれている内容を簡単にテキスト形式で取得できました。
2. PDFファイルを分割する
大きなPDFファイルを、ページ単位で小さなファイルに分割したいことはありませんか。例えば、大学のレポートをページごとに分けて提出する場合などに便利です。
# PDFファイルの分割
reader = pypdf.PdfReader("sample.pdf")
# ページ数取得
pdf_pages = len(reader.pages)
for i in range(0, pdf_pages):
writer = pypdf.PdfWriter()
slide = reader.pages[i]
writer.add_page(slide)
writer.write(f"{i+1}ページ目.pdf")このコードは、sample.pdfを1ページずつ別々のPDFファイルに分割します。len(reader.pages)で全体のページ数を取得し、forループを使ってページ数分の処理を繰り返します。
各ループで、pypdf.PdfWriter()を使って新しいPDFファイルを作成し、writer.add_page(slide)で1ページ分の内容を追加します。そして、writer.write(f"{i+1}ページ目.pdf")で、「1ページ目.pdf」、「2ページ目.pdf」というように、ページ番号を含むファイル名で保存します。
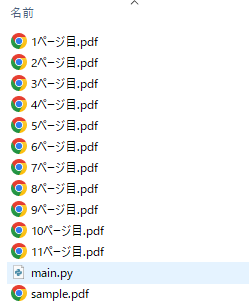
同フォルダ内にページ数分のPDFファイルが作成されています。
3. 複数のPDFファイルを結合する
前のステップで分割したPDFファイルを、再び1つのファイルにまとめたいと思います。例えば、各章を別々のPDFで管理している本を、1つのファイルにまとめるといった使い方ができます。
# 複数のPDFファイルの結合
pdf_files = ["1ページ目.pdf", "2ページ目.pdf", "3ページ目.pdf"]
writer = pypdf.PdfWriter()
for pdf in pdf_files:
writer.append(pdf)
writer.write("new_file.pdf")このコードは、pdf_filesリストに格納されている複数のPDFファイルを1つにまとめます。forループを使って各ファイルを順番にwriter.append(pdf)で追加し、最後にwriter.write("new_file.pdf")で結合されたファイルを保存します。
ファイルの順番は、リストの順番通りになります。つまり、「1ページ目.pdf」、「2ページ目.pdf」、「3ページ目.pdf」の順に結合されます。ファイルの順番を変えたい場合は、リストの順番を変更すればOKです。
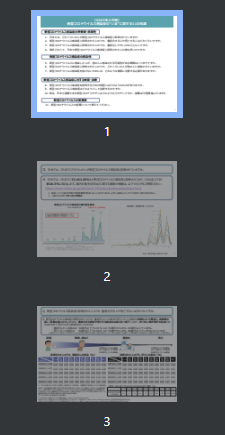
作成されたファイルを見ると3ページが結合されています。
4. PDFをWordファイルに変換する
PDFの内容を編集したい場合、Wordファイルにするとやりやすいですよね。そんな時にも、Pythonが役立ちます。
from pdf2docx import Converter
pdf_file = "new_file.pdf"
docx_file = "output.docx"
cv = Converter(pdf_file)
cv.convert(docx_file)
cv.close()このコードは、new_file.pdfをWordファイル(.docx形式)に変換します。pdf2docxモジュールのConverterクラスを使用し、cv.convert(docx_file)で変換を実行します。変換が完了したら、cv.close()でコンバーターを閉じます。
作成されたファイルを見るとWord形式に変換されています。
まとめ
以上、PythonによるPDF操作の基本を解説しました。ここで紹介した方法を組み合わせれば、さまざまな場面でPDFファイルを効率的に扱えるようになります。
例えば、大量のPDFレポートからキーワードを含むページだけを抽出し、1つのファイルにまとめる、といった高度な操作も可能です。また、今回は1ページ目のみからテキストを抽出しましたが、全ページから抽出することもできます。
Pythonの力を借りれば、PDFファイルを思いのままに操ることができます。面倒だと思っていた作業が自動化され、効率的に仕事や学習を進められるはずです。プログラミングに挑戦して、PDFファイルを自在に操作してみてください。