この記事では、Pythonを使ってAmazonのオーディブルベストセラーリストからデータを取得し、CSVファイルに保存する方法を解説します。今回はウェブスクレイピングでよく使われるSeleniumを使用していきます。必要なライブラリのインポートからデータの取得、ファイルへの書き込みまでの手順を詳しく説明します。

コード全体
from selenium import webdriver
from selenium.webdriver.common.by import By
import csv
# 変数定義-----------
AMAZON_URL1="https://www.amazon.co.jp/gp/bestsellers/audible"
AMAZON_URL2="https://www.amazon.co.jp/gp/bestsellers/audible/ref=zg_bs_pg_2_audible?ie=UTF8&pg=2"
#ドライバー定義、データ取得 ---------
options=webdriver.ChromeOptions()
options.add_experimental_option("detach",True)
titles=[]
urls=[]
authors=[]
def get_content(amazon_url):
driver= webdriver.Chrome(options=options)
driver.get(amazon_url)
get_titles=driver.find_elements(By.CSS_SELECTOR,value="#gridItemRoot div > a > span > div")
get_urls=driver.find_elements(By.CSS_SELECTOR,value="#gridItemRoot div > a")
get_authors=driver.find_elements(By.CSS_SELECTOR,value="#gridItemRoot div > div:nth-child(2) > span > div")
for i in range(0,len(get_titles)):
titles.append(get_titles[i].text)
urls.append(get_urls[i].get_attribute("href"))
authors.append(get_authors[i].text)
driver.quit()
get_content(AMAZON_URL1)
get_content(AMAZON_URL2)
# csv書き込み-----------
with open("Day82~Portfolio/Day93_web_scraping/selen-book-list.csv",mode="w",newline="",encoding="utf-8-sig")as f:
writer=csv.writer(f)
writer.writerow(["number","title","author","url"])
for i in range(0,len(titles)):
writer.writerow([i+1,titles[i],authors[i],urls[i]])
各記述の解説
1. 必要なライブラリのインポート
from selenium import webdriver
from selenium.webdriver.common.by import By
import csvseleniumはウェブブラウザを自動操作するためのライブラリです。ByはWebページ上の要素を特定するためのライブラリです。csvはCSVファイルを扱うためのライブラリです。
2. 変数定義
AMAZON_URL1="https://www.amazon.co.jp/gp/bestsellers/audible"
AMAZON_URL2="https://www.amazon.co.jp/gp/bestsellers/audible/ref=zg_bs_pg_2_audible?ie=UTF8&pg=2"- スクレイピング(データ取得)対象のURLを定義しています。
3. Chromeドライバーの設定
options=webdriver.ChromeOptions()
options.add_experimental_option("detach",True)- ChromeOptions()はブラウザの起動方式や動作をカスタマイズするクラスです。
- “detach”は、Chromeをseleniumが終了しても開いた状態に設定しています。目的に応じて設定してください。
そのほかのオプションの参考になります。利用シーンに応じて設定していきます。
# ブラウザを表示せずにバックグラウンドで実行
options.add_argument('--headless')
# ブラウザのウィンドウサイズを設定
options.add_argument('--window-size=1920,1080')
# ポップアップブロックを無効化
options.add_argument('--disable-popup-blocking')4. データ保存用のリスト準備
titles=[]
urls=[]
authors=[]- 取得したデータを保存するための空のリストを用意します。
5. get_content関数の定義
def get_content(amazon_url):
driver= webdriver.Chrome(options=chrom_options)
driver.get(amazon_url)
get_titles=driver.find_elements(By.CSS_SELECTOR,value="#gridItemRoot div > a > span > div")
get_urls=driver.find_elements(By.CSS_SELECTOR,value="#gridItemRoot div > a")
get_authors=driver.find_elements(By.CSS_SELECTOR,value="#gridItemRoot div > div:nth-child(2) > span > div")
for i in range(0,len(get_titles)):
titles.append(get_titles[i].text)
urls.append(get_urls[i].get_attribute("href"))
authors.append(get_authors[i].text)
driver.quit()- この関数は指定されたURLからデータを取得します。
- driverの初期化時にoptionを設定し指定されたURLにアクセスします。
- find_elements()で条件に合致するHTML要素をリストで取得します。合致するものがない場合は、空のリストを返します。find_element()の場合は合致した最初の要素のみで、ない場合はエラーが発生。
- By.CSS_SELECTORは、対処の要素をCSSセレクタで指定をします。IDやCLASS、XPATHで指定することもできます。
- 要素はリストで取得されるので、ループ文で1つずつ抽出し空のリストへ追加します。.textは文章、get_attribute()はメタデータを取得します。
- driver.quitでブラウザを閉じます。
(補足)要素パスの取得方法
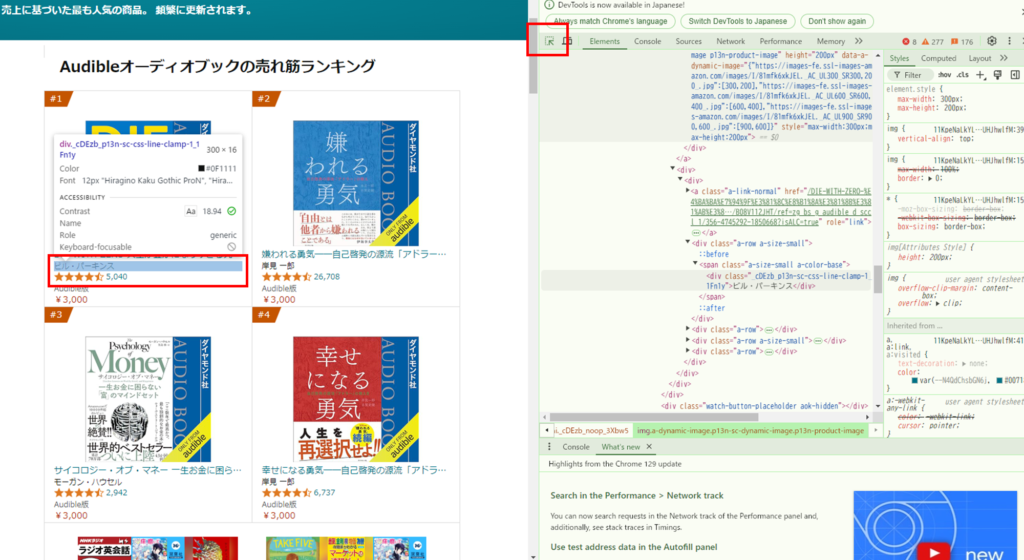
CSSセレクター、XPATHなどはブラウザの開発者ツールで簡単に確認できます。
1.Chromeの「F12」を押し開発者ツールを開きます。左上の矢印をクリックして、パスを取得したい要素にカーソルを持っていくとフォーカスが当たります。
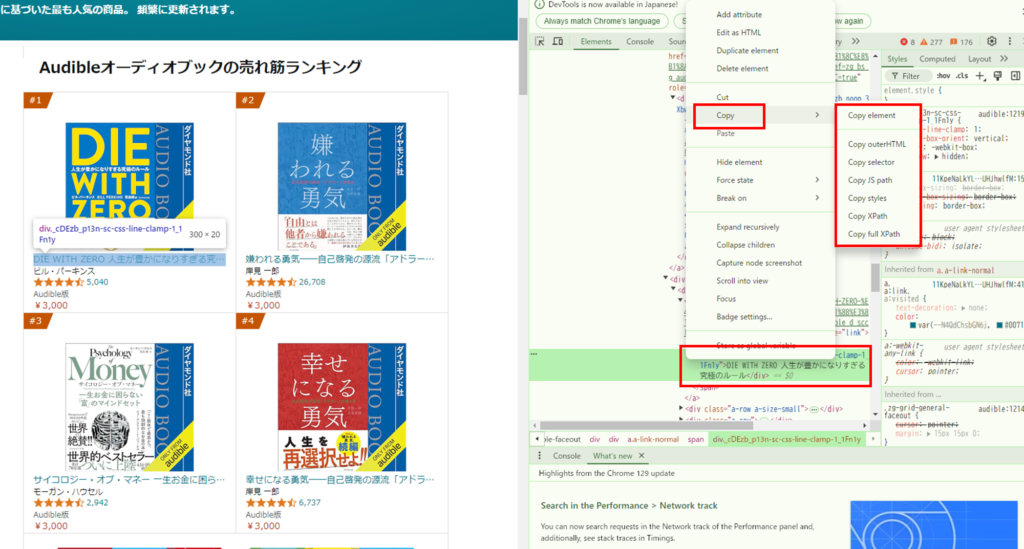
2.フォーカスが当たると右のエディタに該当の要素が表示されるので、右クリックでコピーを選択するとパスが取得できます。
7. データ取得の実行
get_content(AMAZON_URL1)
get_content(AMAZON_URL2)- 2つのURLに対してデータ取得を実行します。
8. CSVファイルへの書き込み
with open("Day82~Portfolio/Day93_web_scraping/selen-book-list.csv",mode="w",newline="",encoding="utf-8-sig")as f:
writer=csv.writer(f)
writer.writerow(["number","title","author","url"])
for i in range(0,len(titles)):
writer.writerow([i+1,titles[i],authors[i],urls[i]]) - 取得したデータをCSVファイルに書き込みます。mode=”w”,newline=””,encoding=”utf-8-sig”は書き込みモードで改行なし、UTF8での書き込みを指定しています。
- ファイルを開き、ヘッダー行を書き込んだ後、各データ行を書き込みます。
まとめ
このプログラムは、ウェブスクレイピングの基本的な流れを示しています。URLにアクセスし、必要な情報を取得し、その情報をファイルに保存するという一連の処理を行っています。
初心者の方にとっては、SeleniumやCSVの扱い方など、新しい概念がたくさん出てくるかもしれません。しかし、各ステップを順に追っていけば、全体の流れを理解することができるでしょう。